
 by
by A graph database is a NoSQL database that uses graphs or networks to store data. The graph database model differs from the relational model in what it considers a primary key and what relationships between records are first class citizens.
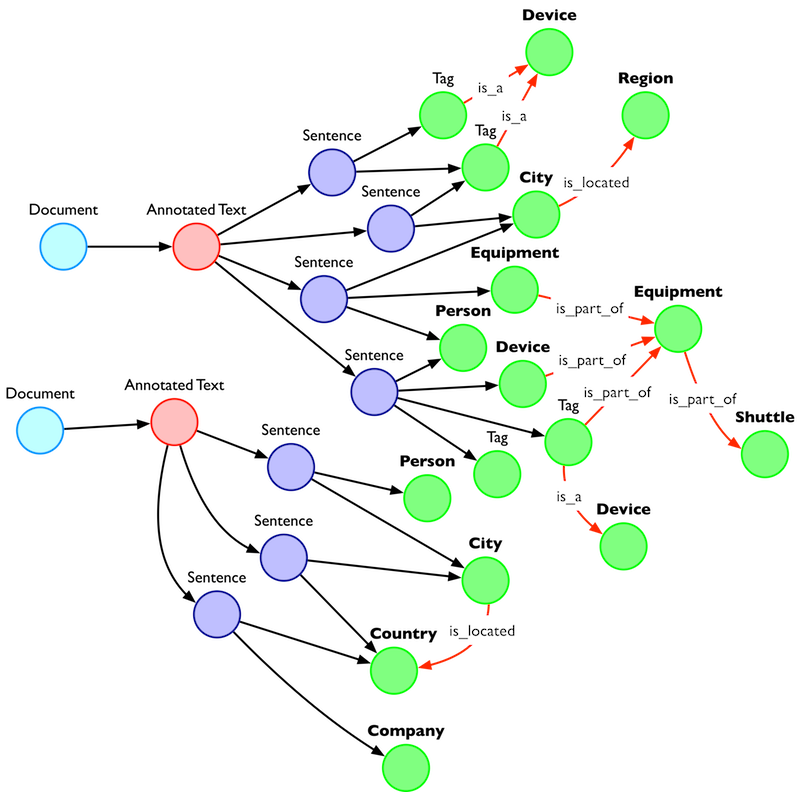
Each entity within a graph is a vertex with a unique identifier referred to as an ID. Because every vertex has a unique ID, you can find every relationship or connection between two vertices.
It is critical to research the question “what is graph database” before you implement it. Graph databases are suited to implement the storage layer of semantic web projects because they offer an intuitive means of representing relationships and interconnections between large volumes of data.
Contents
No Constrain to Database Growth
Typical applications for graph databases include problems with social networks, master data management (MDM), recommendation engines, fraud detection, and business intelligence.
Usage of graph databases has grown by over 100% per year since 2007, making them so compelling now for big data applications. Graphs do not have a primary key in the traditional sense because every interaction between two vertices is considered significant.
Because there are no primary keys to constrain database growth and define what relationships exist, it is possible to create a graph containing an infinite number of vertices. Users must define every edge or relationship before the data model is created.
This means each application must identify what is truly important within the data, such as vertex IDs and what attributes (e.g., names, birth dates) are the key for each vertex.
Works With Big Data Applications
So, what is a graph database? The model makes graphs appealing to big data applications because it often eliminates complex joins required in transactional relational databases.
The relationships within the graph provide the context necessary to transform raw, unstructured data into something meaningful. This gives users insight into what’s happening in the data when it is presented graphically.
No Need for Complex Queries
Because of what’s known as property partitioning in graphs, graph databases are easy to scale horizontally by adding servers. By removing what would be required in traditional relational databases that include vital foreign constraints, there is no limitation on how much you can scale and what you can query in a graph database.
This also means data is redundant because there are no primary keys or relationships to define essentials. Although this seems like a disadvantage, it makes graph databases highly available and scalable because they store everything in place instead of creating multiple copies that need to be updated.
Align With What’s Important to the Business
The power of graph databases makes them very useful for knowledge management applications because they can model relationships between entities according to what’s essential to the organization.
By aligning what’s in the data to what is essential, answering questions requiring a multistage query in traditional relational databases becomes easier. This makes it possible to ask what-if questions because you can see the data at different levels of abstraction.
Summary
The factor that makes graph databases so compelling for knowledge management applications is that they make semantic web projects valuable. They make data management more accessible, more organized, and more structured.


